Evidence on good forecasting practices from the Good Judgment Project: an accompanying blog post
webAuthor
kokotajlod
Credibility Rating
3/5
Good(3)Good quality. Reputable source with community review or editorial standards, but less rigorous than peer-reviewed venues.
Rating inherited from publication venue: EA Forum
Relevant to AI safety researchers and policy analysts who rely on forecasting to assess risks and prioritize interventions; draws on the Good Judgment Project's empirical track record to ground best practices in evidence.
Forum Post Details
Karma
79
Comments
14
Forum
eaforum
Forum Tags
ForecastingForum PrizeResearch methodsPhilip Tetlock
Metadata
Importance: 52/100blog postanalysis
Summary
This EA Forum post synthesizes empirical evidence from the Good Judgment Project and related forecasting research to identify practices that improve prediction accuracy. It covers techniques such as aggregation, calibration training, and the use of superforecasters, with implications for decision-making under uncertainty in high-stakes domains.
Key Points
- •Aggregating forecasts from multiple predictors consistently outperforms individual predictions, even simple averaging adds value.
- •Superforecasters—a small subset of highly accurate forecasters—demonstrate that forecasting skill is real and partially trainable.
- •Calibration training and structured analytical techniques (e.g., reference class forecasting) measurably improve forecast accuracy.
- •Actively open-minded thinking and willingness to update on new evidence are key traits of good forecasters.
- •Findings have direct relevance for AI safety and governance communities seeking to make better predictions about future developments.
Cited by 1 page
| Page | Type | Quality |
|---|---|---|
| Good Judgment (Forecasting) | Organization | 50.0 |
Cached Content Preview
HTTP 200Fetched May 30, 202653 KB
# Evidence on good forecasting practices from the Good Judgment Project: an accompanying blog post
By kokotajlod
Published: 2019-02-15
This is a linkpost reproducing [this AI Impacts blog post](https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project-an-accompanying-blog-post/). This post is itself a longer and richer version of the concise summary given in [this AI Impacts page.](https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project/) Readers who don't have time to read the post are encouraged to read the page instead or at least first.
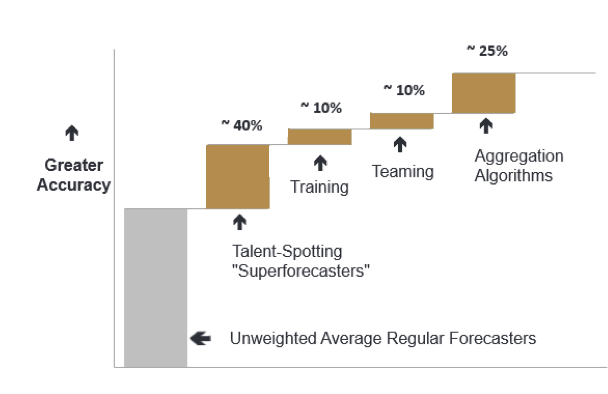
Figure 0: The “four main determinants of forecasting accuracy.” **[1](https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project-an-accompanying-blog-post/#easy-footnote-bottom-1-1260)**
Experience and data from the Good Judgment Project (GJP) provide important evidence about how to make accurate predictions. For a concise summary of the evidence and what we learn from it, see **[this page](http://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project/)**. For a review of _[Superforecasting](https://smile.amazon.com/Superforecasting-Science-Prediction-Philip-Tetlock/dp/0804136718/ref=sr_1_1?ie=UTF8&qid=1541990711&sr=8-1&keywords=superforecasting+the+art+and+science+of+prediction),_ the popular book written on the subject, see [this blog](http://slatestarcodex.com/2016/02/04/book-review-superforecasting/).
This post explores the evidence in more detail, drawing from the book, the academic literature, the older _[Expert Political Judgment](https://smile.amazon.com/Expert-Political-Judgment-Good-Know/dp/0691128715/ref=sr_1_1?ie=UTF8&qid=1541990738&sr=8-1&keywords=expert+political+judgment)_ book, and an interview with a superforecaster. Readers are welcome to skip around to parts that interest them:
1\. The experiment
------------------
[IARPA](https://www.iarpa.gov/) ran a forecasting tournament from 2011 to 2015, in which five teams plus a control group gave probabilistic answers to hundreds of questions. The questions were generally about potential geopolitical events more than a month but less than a year in the future, e.g. “Will there be a violent incident in the South China Sea in 2013 that kills at least one person?” The questions were carefully chosen so that a reasonable answer would be somewhere between 10% and 90%.**[2](https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project-an-accompanying-blog-post/#easy-footnote-bottom-2-1260)** The forecasts were scored using the _original_ [Brier score](https://en.wikipedia.org/wiki/Brier_score)—more on that in Section 2.**[3](https://aiimpacts.org/evidence-on-good-forecasting-practices-from-the-good-judgment-project-an-accompanying-blog-post/#easy-footnote-bottom-3-1260)**
The winning team was the GJP, run by Philip
... (truncated, 53 KB total)Resource ID:
14f0f4189a6e68d4 | Stable ID: sid_0cSynlP5HE