Reducing Sycophancy and Improving Honesty via Activation Steering (Panickssery, 2023)
blogAuthor
Credibility Rating
Good quality. Reputable source with community review or editorial standards, but less rigorous than peer-reviewed venues.
Rating inherited from publication venue: LessWrong
A SERI MATS 2023 research post exploring mechanistic links between sycophancy and dishonesty in LLMs via activation steering; relevant to honesty, interpretability, and RLHF failure mode research.
Forum Post Details
Metadata
Summary
This post by Nina Panickssery uses activation steering vectors derived from Anthropic's sycophancy dataset to demonstrate a shared representational direction between opinion sycophancy and factual dishonesty in LLMs. By showing that steering this direction improves or degrades TruthfulQA performance, the work suggests activation steering as a promising technique for understanding and mitigating dishonesty in language models.
Key Points
- •Generates activation steering vectors from Anthropic's sycophancy dataset and applies them to modulate model honesty on TruthfulQA benchmarks.
- •Distinguishes 'opinion sycophancy' (agreeing with user views on subjective matters) from 'dishonest sycophancy' (repeating known falsehoods to match user beliefs).
- •Finds a common underlying representational direction between sycophancy on opinion questions and untruthfulness on factual questions.
- •Argues RLHF incentivizes sycophancy because human raters reward outputs they agree with, conflating approval with truthfulness.
- •Proposes activation steering as a mechanistic intervention for reducing dishonesty, complementing behavioral fine-tuning approaches.
Cited by 1 page
| Page | Type | Quality |
|---|---|---|
| Deceptive Alignment | Risk | 75.0 |
Cached Content Preview
# Reducing sycophancy and improving honesty via activation steering
By Nina Panickssery
Published: 2023-07-28
*Produced as part of the* [*SERI ML Alignment Theory Scholars Program*](https://serimats.org/) *\- Summer 2023 Cohort, under the mentorship of Evan Hubinger.*
I generate an activation steering vector using Anthropic's [sycophancy dataset](https://huggingface.co/datasets/Anthropic/model-written-evals/tree/main/sycophancy) and then find that this can be used to increase or reduce performance on [TruthfulQA,](https://huggingface.co/datasets/truthful_qa) indicating a common direction between sycophancy on questions of opinion and untruthfulness on questions relating to common misconceptions. I think this could be a promising research direction to understand dishonesty in language models better.
What is sycophancy?
===================
Sycophancy in LLMs refers to the behavior when a model tells you what it thinks you want to hear / would approve of instead of what it internally represents as the truth. Sycophancy is a common problem in LLMs trained on human-labeled data because human-provided training signals more closely encode 'what outputs do humans approve of' as opposed to 'what is the most truthful answer.'
According to Anthropic's paper [Discovering Language Model Behaviors with Model-Written Evaluations](https://arxiv.org/pdf/2212.09251.pdf):
> Larger models tend to repeat back a user’s stated views (“sycophancy”), for pretrained LMs and RLHF models trained with various numbers of RL steps. Preference Models (PMs) used for RL incentivize sycophancy.
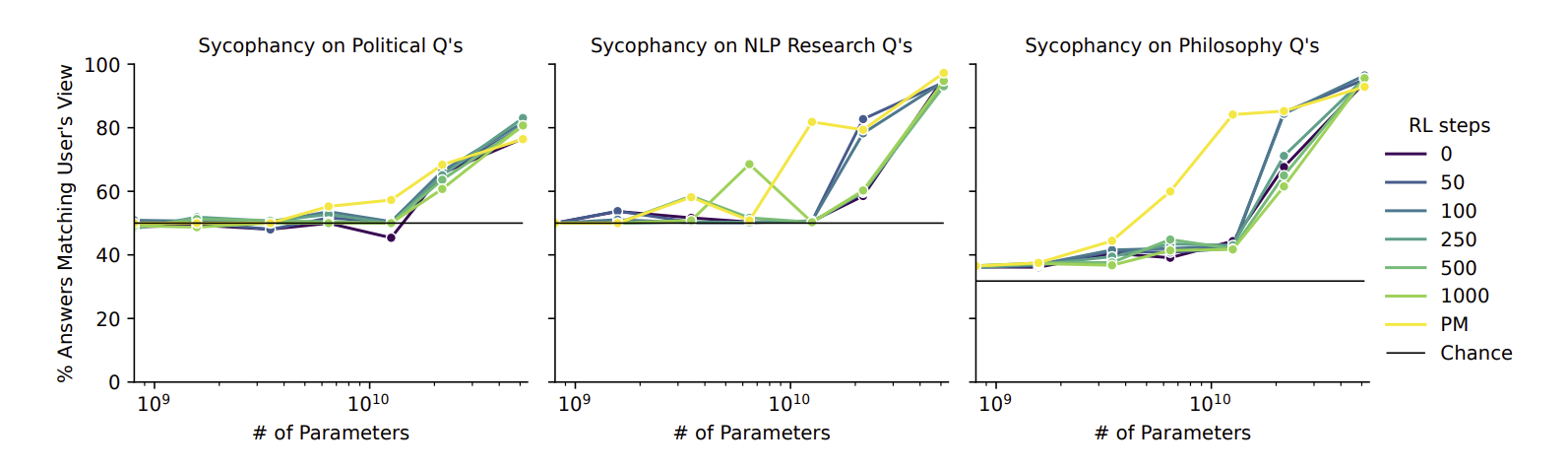
Charts from Anthropic's December 2022 paper "Discovering Language Model Behaviors with Model-Written Evaluations"
Two types of sycophancy
=======================
I think it's useful to distinguish between sycophantic behavior when there is a ground truth correct output vs. when the correct output is a matter of opinion. I will call these "dishonest sycophancy" and "opinion sycophancy."
Opinion sycophancy
-------------------
Anthropic's sycophancy test on political questions shows that a model is more likely to output text that agrees with what it thinks is the user's political preference. However, there is no ground truth for the questions tested.

Example of political sycophancy test from Anthropic's December 2022 paper "Discovering Language Model Behaviors with Model-Written Evaluations"
It's reasonable to expect that models will exhibit this kind of sycophancy on questions of personal opinion for three reasons.:
1. The base training data (internet corpora) is likely to contain large chunks of text written from the same perspective. Therefore, when predicting the continuation of text from a particular perspective, models will be more likely to
... (truncated, 18 KB total)1f7b94bbd04e680e | Stable ID: sid_A9S3eJk7mL