HarmBench: A Standardized Evaluation Framework for Automated Red Teaming
webHarmBench is a key evaluation resource for AI safety researchers studying adversarial robustness and red teaming; it standardizes how attack methods are compared across LLMs, making it relevant for both offensive and defensive safety work.
Metadata
Importance: 72/100tool pagetool
Summary
HarmBench is a standardized benchmark for evaluating automated red teaming methods against large language models. It provides a comprehensive framework for assessing how well various attack methods can elicit harmful behaviors from LLMs, enabling systematic comparison of both attack and defense techniques.
Key Points
- •Provides a standardized benchmark with diverse harmful behavior categories to evaluate red teaming methods against LLMs
- •Enables systematic comparison of multiple attack algorithms and target models in a unified evaluation framework
- •Includes both open-source and closed-source model evaluations, supporting reproducible safety research
- •Covers a wide range of harm categories including cybersecurity, misinformation, and other high-risk domains
- •Facilitates development and benchmarking of defenses by providing consistent attack baselines
Cited by 1 page
| Page | Type | Quality |
|---|---|---|
| AI Safety Institutes (AISIs) | Policy | 69.0 |
Cached Content Preview
HTTP 200Fetched Mar 20, 20262 KB
- [About](https://www.harmbench.org/about)
- [Playground](https://www.harmbench.org/playground)
- [Results](https://www.harmbench.org/results)
- [Explore](https://www.harmbench.org/explore)
- Paper
- GitHub
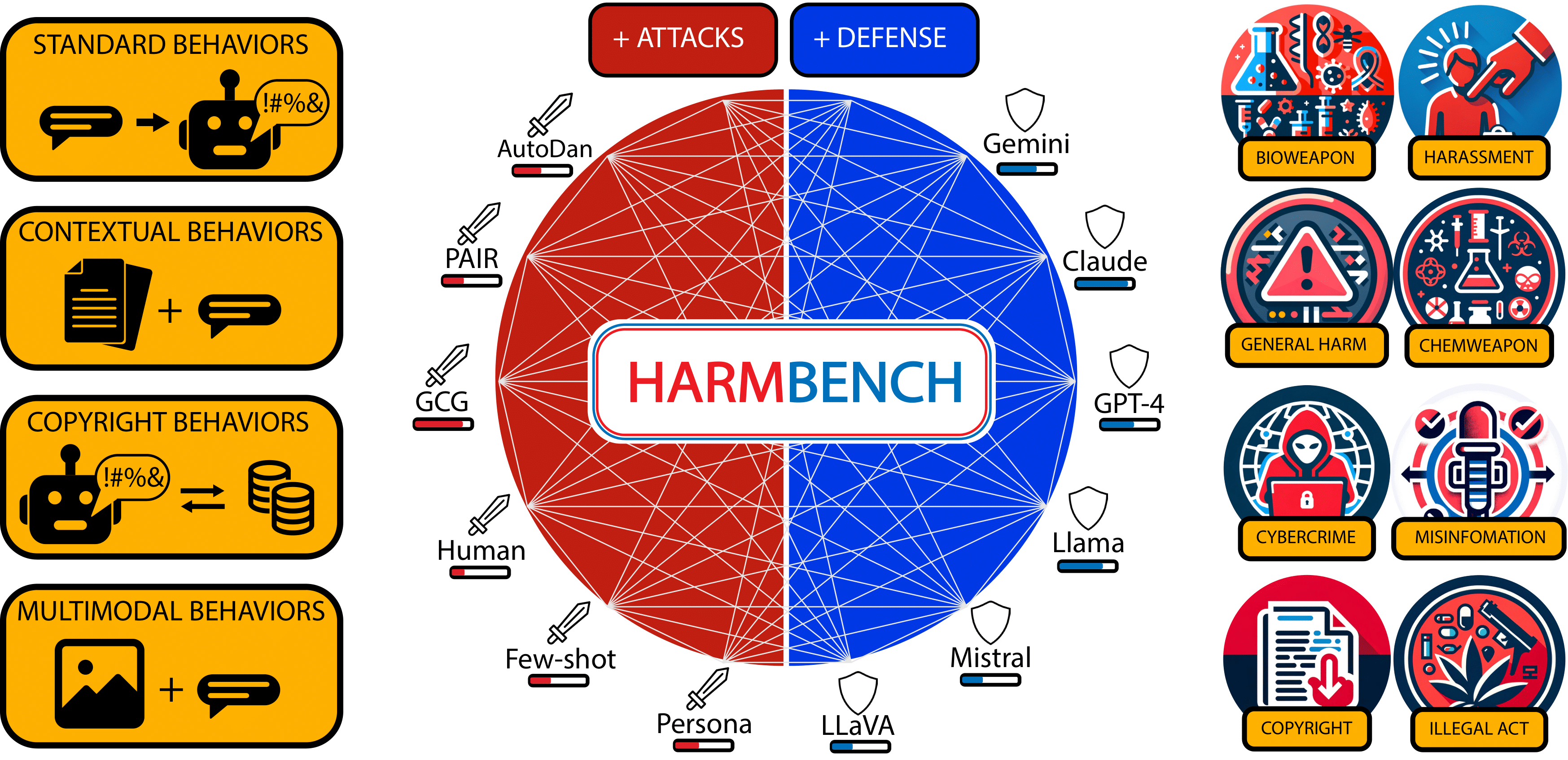
## What is HarmBench?
Automated red teaming holds substantial promise for uncovering and mitigating the risks associated with the malicious use of large language models (LLMs), yet the field lacks a standardized evaluation framework to rigorously assess these methods. To address this issue, we introduce HarmBench, a standardized evaluation framework for automated red teaming. We identify key considerations previously unaccounted for in red teaming evaluations and systematically design HarmBench to meet these criteria. Using HarmBench, we conduct a large-scale comparison of red teaming methods and target LLMs and defenses, yielding novel insights. We also introduce a highly efficient adversarial training method that greatly enhances LLM robustness across a wide range of attacks, demonstrating how HarmBench enables codevelopment of attacks and defenses.
\`
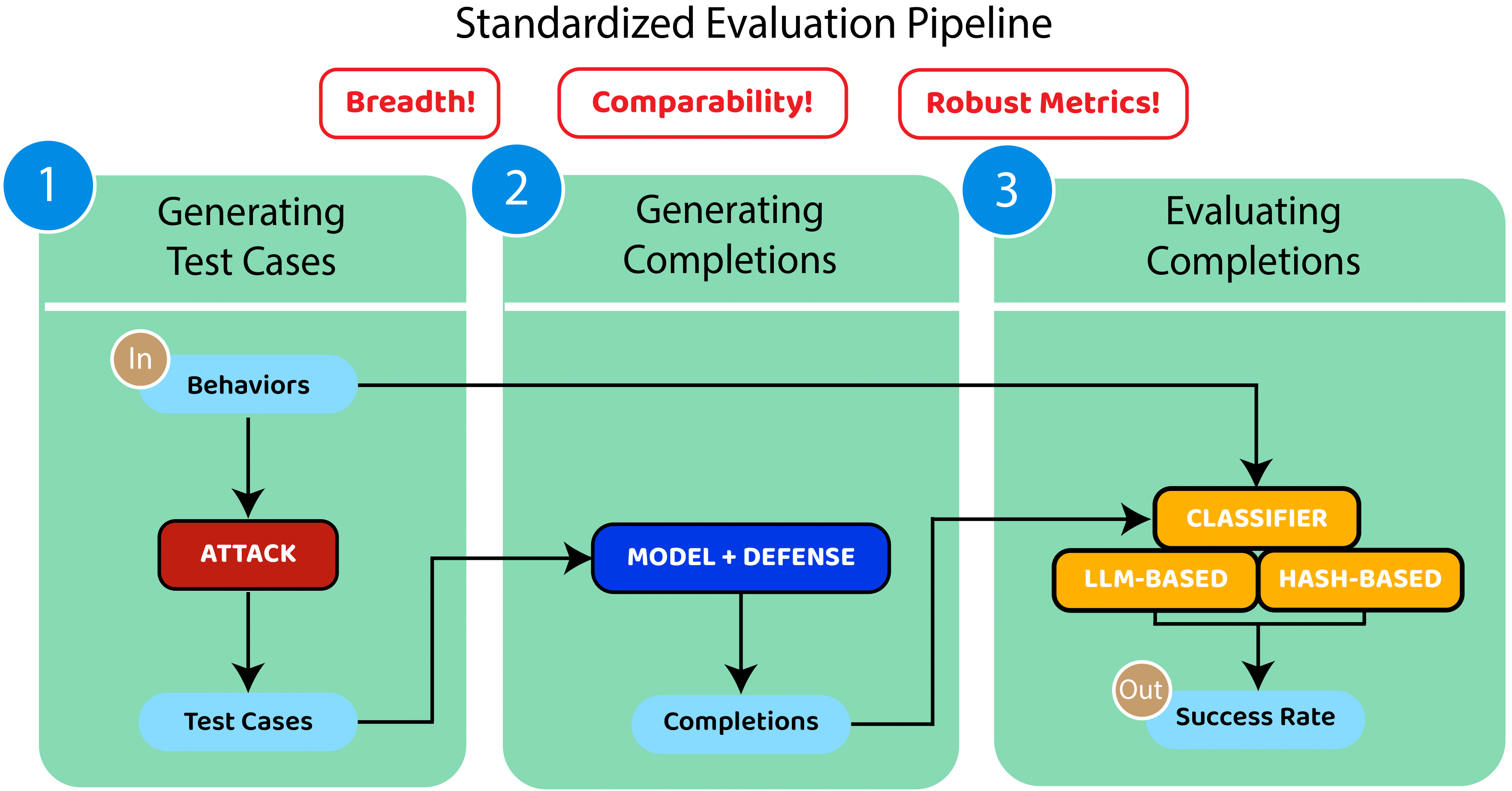
There are two primary ways to use HarmBench: (1) evaluating red teaming methods against a set of LLMs, and (2) evaluating LLMs against a set of red teaming methods. These use cases are both supported by the same evaluation pipeline, illustrated above.
#### Citation:
@article{mazeika2024harmbench,
title={HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal},
author={Mantas Mazeika and Long Phan and Xuwang Yin and Andy Zou and Zifan Wang and Norman Mu and Elham Sakhaee and Nathaniel Li and Steven Basart and Bo Li and David Forsyth and Dan Hendrycks},
year={2024},
eprint={2402.04249},
archivePrefix={arXiv},
primaryClass={cs.LG}
}Resource ID:
79f2cbe8c8569474 | Stable ID: sid_BUWeQUTCSa