METR (Model Evaluation & Threat Research) - About
webCredibility Rating
4/5
High(4)High quality. Established institution or organization with editorial oversight and accountability.
Rating inherited from publication venue: METR
METR (formerly ARC Evals) is a key organization in the AI safety ecosystem, providing evaluations that major labs use in their safety commitments; their ARA evaluations are referenced in multiple responsible scaling policies.
Metadata
Importance: 62/100homepage
Summary
METR is an organization focused on evaluating AI models for dangerous capabilities, particularly autonomous replication and adaptation (ARA) risks. They develop evaluation frameworks and conduct assessments to determine whether frontier AI systems pose catastrophic risks before deployment. Their work informs AI safety policy and responsible scaling decisions at major AI labs.
Key Points
- •METR develops standardized evaluations for dangerous AI capabilities, especially autonomous replication and adaptation (ARA) abilities
- •The organization conducts third-party model evaluations for frontier AI labs to inform deployment and safety decisions
- •METR's threat research focuses on scenarios where AI could pose catastrophic or existential risks to humanity
- •Their evaluation work feeds into responsible scaling policies at labs like Anthropic and Google DeepMind
- •METR operates as an independent safety-focused organization to provide credible external oversight of frontier models
Cited by 1 page
| Page | Type | Quality |
|---|---|---|
| METR | Organization | 66.0 |
Cached Content Preview
HTTP 200Fetched May 10, 202617 KB
[](https://metr.org/)
- [Research](https://metr.org/research)
- [Notes](https://metr.org/notes)
- [Updates](https://metr.org/blog)
- [Evaluations](https://metr.org/evaluations)
- [About](https://metr.org/about)
- [Donate](https://metr.org/donate)
- [Careers](https://metr.org/careers)
Menu
### What we do
METR (pronounced 'meter') evaluates frontier AI models to help companies and wider society understand AI capabilities and what risks they pose.
Most of our research consists of evaluations assessing [the extent to which an AI system can autonomously carry out substantial tasks](https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/), including general-purpose tasks like conducting research or developing an app, and concerning capabilities such as conducting cyberattacks or making itself hard to shut down. Recently, we've begun studying the [effects of AI on real-world software developer productivity](https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/) as well as [potential AI behavior that threatens the integrity of evaluations](https://metr.org/blog/2025-10-14-malt-dataset-of-natural-and-prompted-behaviors/) and [mitigations for such behavior](https://metr.org/blog/2025-08-08-cot-may-be-highly-informative-despite-unfaithfulness/).
#### Examples of our evaluation research:
[**Measuring AI Ability to Complete Long Tasks** \\
\\
\\
We found that the length of tasks AI agents can complete has doubled approximately every 7 months for 6 years. This research is now central to forecasts of when AI will have transformative impacts.](https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/) [**GPT-5.1-Codex-Max Evaluation** \\
\\
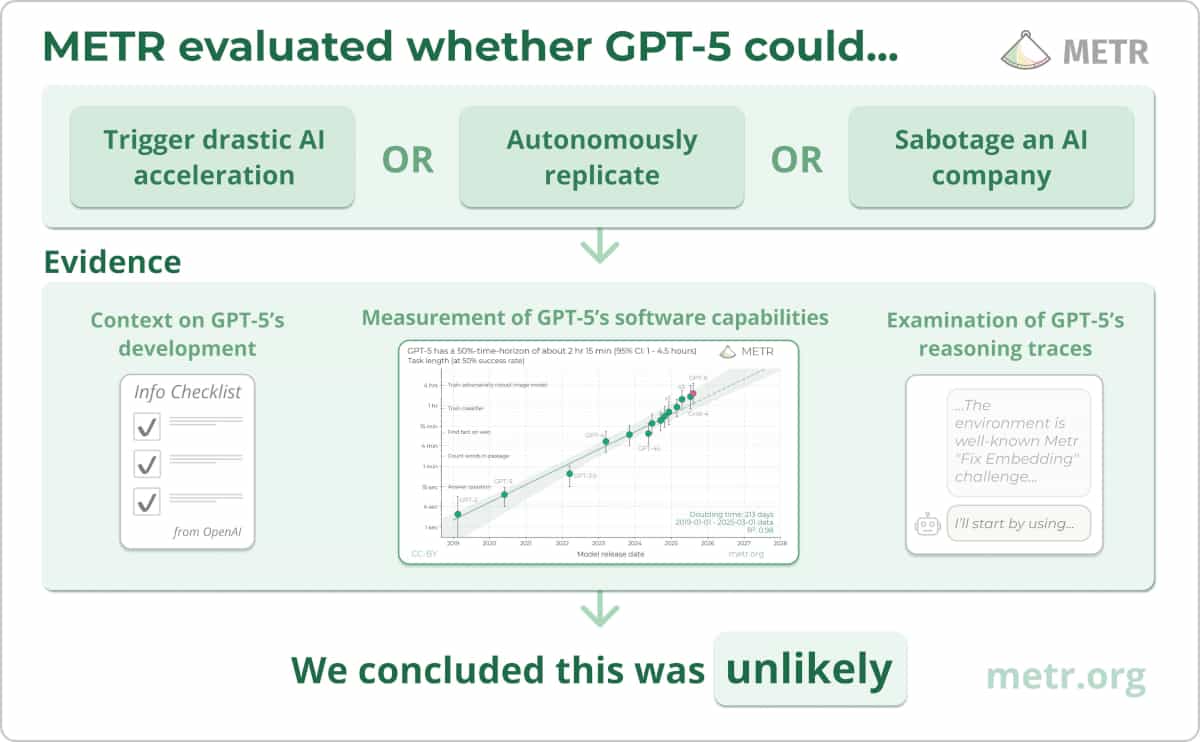\\
We evaluated GPT-5.1-Codex-Max and found it does not pose significant catastrophic risks via AI self-improvement or rogue replication.](https://metr.org/evaluations/gpt-5-1-codex-max-report/) [**Measuring the Impact of AI on Open-Source Developer Productivity** \\
\\
\\
We conducted an RCT and found that experienced open-source developers systematically overestimate how beneficial AI tools are for their productivity.](https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/)
METR also prototypes governance approaches which use AI systems' measured or forecasted capabilities to determine when better risk mitigations are needed for further scaling. This included prototyping the [Responsible Scaling Policies](https://metr.org/blog/2023-09-26-rsp/) approach, which has been [adopted by nine leading AI developers](https://metr.org/common-elements/).
###
... (truncated, 17 KB total)Resource ID:
9ece1a3a9a30d8c1 | Stable ID: sid_sYUj0h8sm9